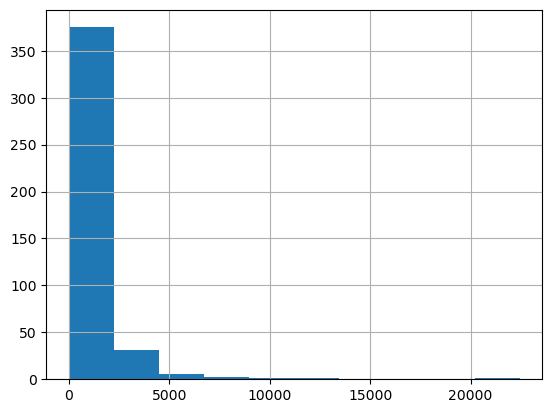
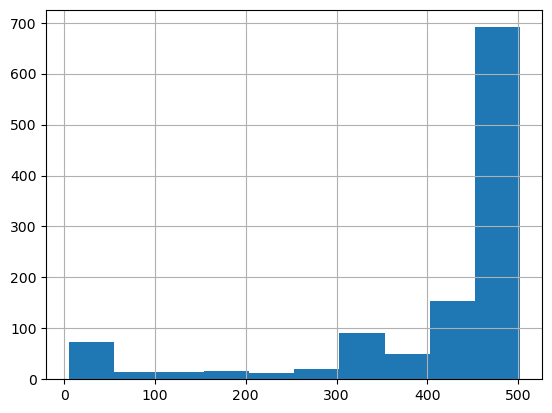
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
| max_tokens = 500
def remove_newlines(serie):
serie = serie.str.replace('\n', ' ')
serie = serie.str.replace('\\n', ' ')
serie = serie.str.replace(' ', ' ')
serie = serie.str.replace(' ', ' ')
return serie
def create_context(
question, df, max_len=1800, size="ada"
):
"""
寻找最相似的文本段
"""
q_embeddings = openai.Embedding.create(input=question, engine='text-embedding-ada-002')['data'][0]['embedding']
df['distances'] = distances_from_embeddings(q_embeddings, df['embeddings'].values, distance_metric='cosine')
returns = []
cur_len = 0
for i, row in df.sort_values('distances', ascending=True).iterrows():
cur_len += row['n_tokens'] + 4
if cur_len > max_len:
break
returns.append(row["text"])
return "\n\n###\n\n".join(returns)
def split_into_many(text, max_tokens = max_tokens):
sentences = re.split('[.。!?!?]',text)
n_tokens = [len(tokenizer.encode(" " + sentence)) for sentence in sentences]
chunks = []
tokens_so_far = 0
chunk = []
for sentence, token in zip(sentences, n_tokens):
if tokens_so_far + token > max_tokens:
chunks.append(". ".join(chunk) + ".")
chunk = []
tokens_so_far = 0
if token > max_tokens:
continue
chunk.append(sentence)
tokens_so_far += token + 1
return chunks
def answer_question(
df,
model="text-davinci-003",
question="你有什么问题",
max_len=1800,
size="ada",
debug=False,
max_tokens=1800,
stop_sequence=None,
use_GPT=False
):
"""
回答问题
"""
context = create_context(
question,
df,
max_len=max_len,
size=size,
)
if debug:
print("Context:\n" + context)
print("\n\n")
print(f"Answer the question based on the context below, and if the question can't be answered based on the context, say \"I don't know\"\n\nContext: {context}\n\n---\n\nQuestion: {question}\nAnswer:")
if use_GPT:
completion = openai.ChatCompletion.create(model="gpt-3.5-turbo",messages=[
{"role": "user", "content": f"Answer the question based on the context below, and if the question can't be answered based on the context, say \"I don't know\"\n\nContext: {context}\n\n---\n\nQuestion: {question}\nAnswer:"}])
return completion.to_dict()["choices"][0]["message"]["content"]
try:
response = openai.Completion.create(
prompt=f"Answer the question based on the context below, and if the question can't be answered based on the context, say \"I don't know\"\n\nContext: {context}\n\n---\n\nQuestion: {question}\nAnswer:",
temperature=0,
max_tokens=max_tokens,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
stop=stop_sequence,
model=model,
)
return response["choices"][0]["text"].strip()
except Exception as e:
print(e)
return ""
|